分享一个爬取网站的小技巧

分享一个爬取网站的小技巧
极客猴有时候,我们很想爬取一个网站的数据。
如果 PC 端的网页的反爬机制太强,我们可以换个思路。
现在很多网站为了满足手机浏览器能正常访问的需求,都会推出手机版的网页。
PC 端抓取数据有难度,我们可以从手机端入手。
你也许听说过,抓取手机 App 端数据就需要搭建手机抓包环境。
那么我们就要屁颠屁颠去抓包搭建?
哈哈,显然不用。
我给大家分享一个小技巧,可以节省搭建环境的时间。
我们的抓取目标是 Web 手机端页面数据,而不是 App 端内的数据。
因此,我们只要使用 PC 浏览器访问手机 Web 页面,就能继续使用 PC 浏览器进行抓包分析。
举个栗子,假如我要抓取淘宝首页的数据。我先用手机浏览器访问淘宝网站。
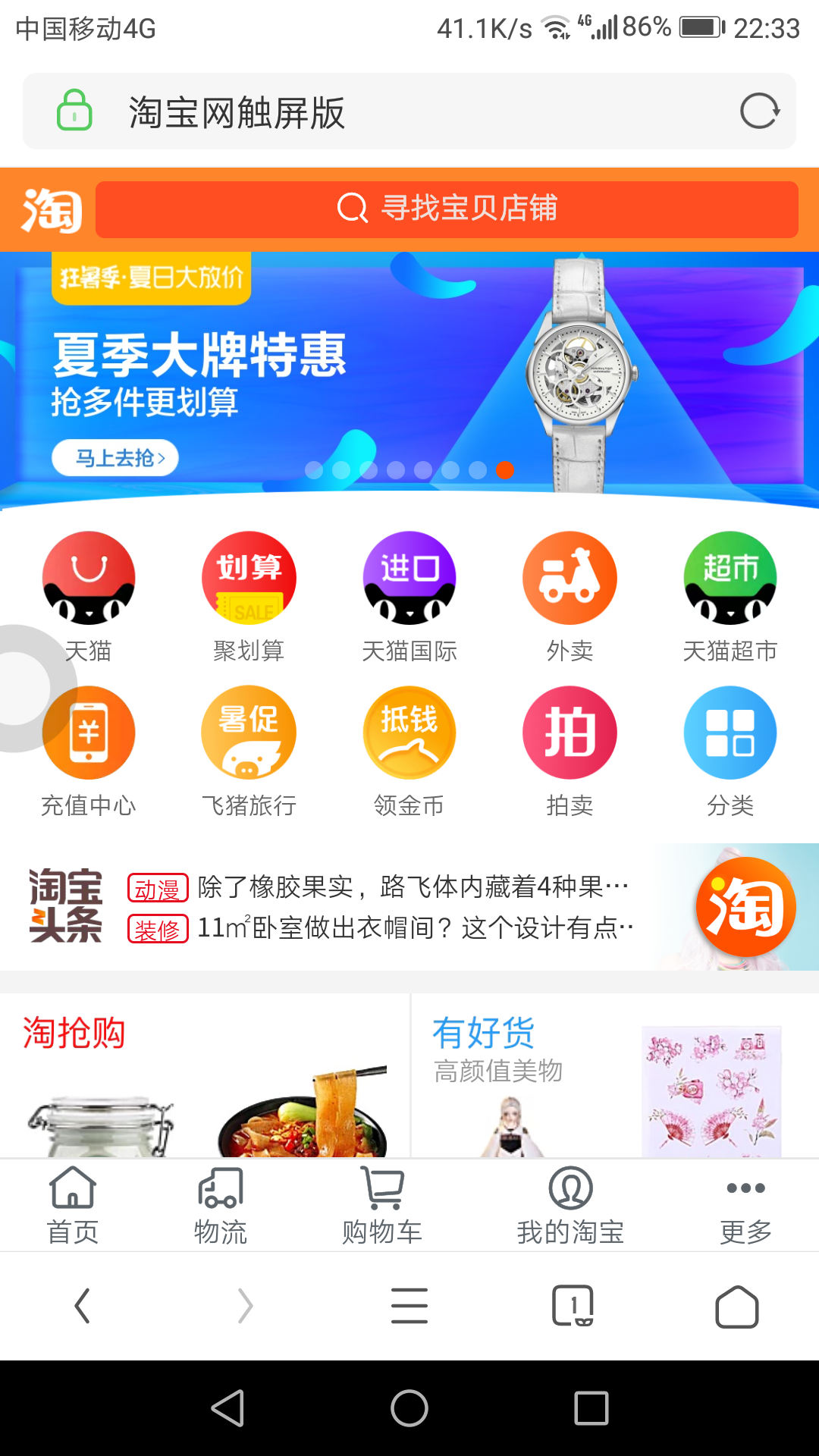
然后获取到手机端淘宝首页的 url 地址。

从图中,我们可知淘宝 web 手机端首页地址是:https://h5.m.taobao.com/。接着我们再用 PC 浏览器访问。
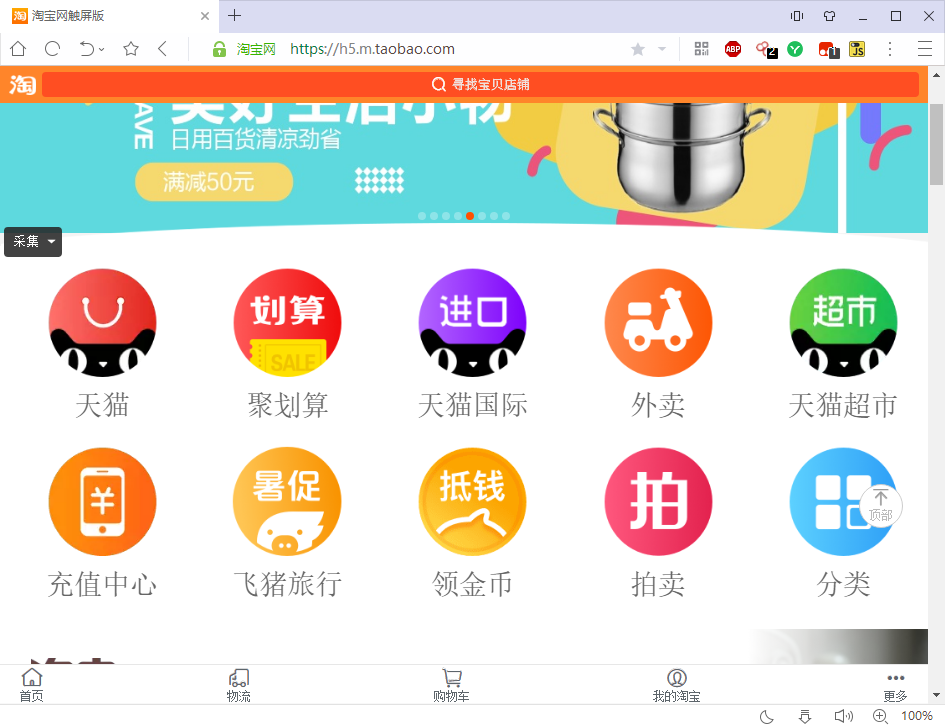
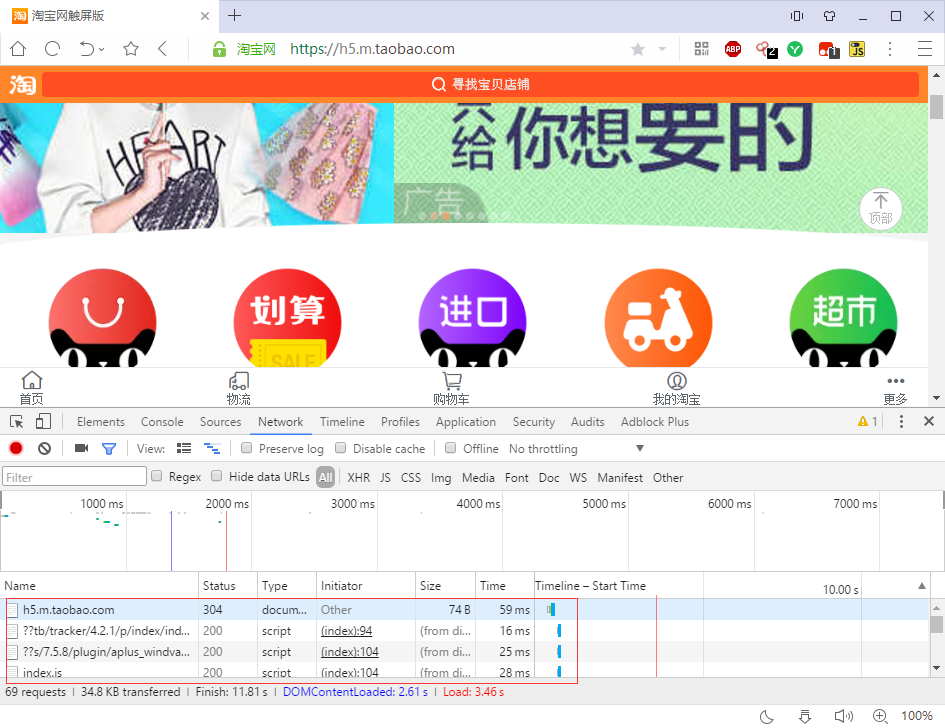
PC 端浏览器能正常访问,说明我们能使用浏览器自带的开发者工具来进行抓包分析。


喜欢这篇文章的人也看了






评论
匿名评论隐私政策
✅ 你无需删除空行,直接评论以获取最佳展示效果






