Python 正则表达式

Python 正则表达式
极客猴我们能够使用 urllib 向网页请求并获取其网页数据。
但是抓取信息数据量比较大,我们可能需要其中一小部分数据。对付刚才的难题,就需要正则表达式出马了。
正则表达式能帮助我们匹配过滤到我们需要的数据,但它学习起来非常枯燥无味。
你可能会说,我还没有开始想学习正则表达式,你就来打击我?
莫慌!
层层递进地学习,一步一个脚印地学习,很快就会学会了。
对于爬虫,我觉得学会最基本的符号就差不多了。
1.正则表达式
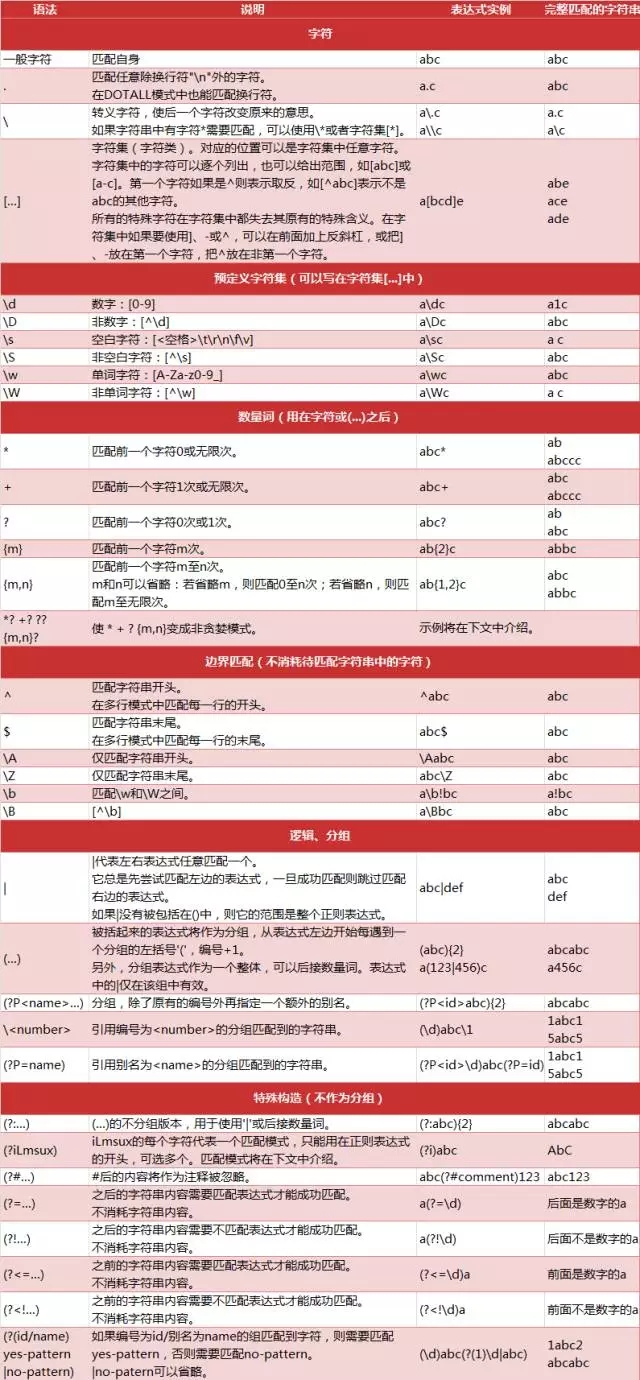
下面是一张关于正则表达式字符的图,图片资料来自CSDN。先把图中字符了解清楚,基本上算是入门。
2.re 模块
Python 自 1.5 版本起通过新增 re (Regular Expression 正则表达式)模块来提供对正则表达式的支持。
使用 re 模块先将正则表达式填充到 Pattern 对象中,再把 Pattern 对象作为参数使用 match 方法去匹配的字符串文本。
match 方法会返回一个 Match 对象,再通过 Match 对象会得到我们的信息并进行操作。
下面介绍几个 re 常用的函数。
2-1.compile 函数
compile 是把正则表达式的模式和标识转化成正则表达式对象,供 match() 和 search() 这两个函数使用。它的函数语法如下:
1 | re.compile(pattern[, flags]) |
- 第一个参数是
pattern,指的正则表达式。 - 第二个参数
flags是匹配模式,是个可选参数。可以使用按位或’|’表示同时生效,也可以在正则表达式字符串中指定。匹配模式有以下几种:
| flag | 描述 |
|---|---|
| re.I(全拼:IGNORECASE) | 忽略大小写(括号内是完整写法,下同) |
| re.M(全拼:MULTILINE) | 多行模式,改变’^’和’$’的行为(参见上图) |
| re.S(全拼:DOTALL) | 点任意匹配模式,改变’.’的行为 |
| re.L(全拼:LOCALE) | 使预定字符类 \w \W \b \B \s \S 取决于当前区域设定 |
| re.U(全拼:UNICODE) | 使预定字符类 \w \W \b \B \s \S \d \D 取决于unicode定义的字符属性 |
| re.X(全拼:VERBOSE) | 详细模式。这个模式下正则表达式可以是多行,忽略空白字符,并可以加入注释。 |
- 该方法返回的结果是一个 Pattern 对象。
2-2.match 函数
match() 函数只在字符串的开始位置尝试匹配正则表达式,也就是说只有在 0 位置匹配成功的话才有返回。如果不是开始位置匹配成功的话,match() 就返回 none。它的函数语法如下:
1 | re.match(pattern, string[, flags]) |
- 第一个参数:匹配的正则表达式
- 第二个参数:要被匹配的字符串
- flags 是可选参数,跟 compile 用法相似
- 匹配成功 re.match 方法返回一个匹配的对象,否则返回None。要想获得匹配结果,既可以使用
groups()函数获取一个包含所有字符串的元组(从 1 到 所含的小组号),也可以使用group(组号)函数获取某个组号的字符串。
match 函数用法的示例代码:
1 | import re |
2-3.search 函数
search() 函数是扫描整个字符串来查找匹配,它返回结果是第一个成功匹配的字符串。
1 | re.search(pattern, string[, flags]) |
参数用法以及返回结果跟match函数用法相同。
search 函数用法的示例代码:
1 | import re |
2-4.findall 函数
findall 函数在字符串中搜索子串,并以列表形式返回全部能匹配的所有子串。
1 | re.findall(pattern, string[, flags]) |
参数用法以及返回结果跟match函数用法相同。
findall 函数用法的示例代码:
1 | import re |














