前面两篇文章介绍 requests 和 xpath 的用法。我们推崇学以致用,所以本文讲解利用这两个工具进行实战。
1.爬取目标
本次爬取的站点选择电影天堂,网址是: www.ydtt8.net。
爬取内容是整个站点的所有电影信息,包括电影名称,导演、主演、下载地址等。具体抓取信息如下图所示:

2.设计爬虫程序
2-1.确定爬取入口
电影天堂里面的电影数目成千上万,电影类型也是让人眼花缭乱。
我们为了保证爬取的电影信息不重复, 所以要确定一个爬取方向。
目前这情况真让人无从下手。
但是,我们点击主页中的【最新电影】选项,跳进一个新的页面。蓦然有种柳暗花明又一村的感觉。
由图可知道,电影天堂有 5 个电影栏目,分别为最新电影、日韩电影、欧美电影、国内电影、综合电影。
每个栏目又有一定数量的分页,每个分页有 25 条电影信息。
那么程序的入口可以有 5 个 url 地址。
这 5 个地址分别对应每个栏目的首页链接。
2-2.爬取思路
知道爬取入口,后面的工作就容易多了。
我通过测试发现这几个栏目除了页面的 url 地址不一样之外,其他例如提取信息的 xpath 路径是一样的。
因此,我把 5 个栏目当做 1 个类,再该类进行遍历爬取。
我这里“最新电影”为例说明爬取思路。
1)请求栏目的首页来获取到分页的总数,以及推测出每个分页的 url 地址;
2)将获取到的分页 url 存放到名为 floorQueue 队列中;
3)从 floorQueue 中依次取出分页 url,然后利用多线程发起请求;
4)将获取到的电影页面 url 存入到名为 middleQueue 的队列;
5)从 middleQueue 中依次取出电影页面 url,再利用多线程发起请求;
6)将请求结果使用 Xpath 解析并提取所需的电影信息;
7)将爬取到的电影信息存到名为 contentQueue 队列中;
8)从 contentQueue 队列中依次取出电影信息,然后存到数据库中。
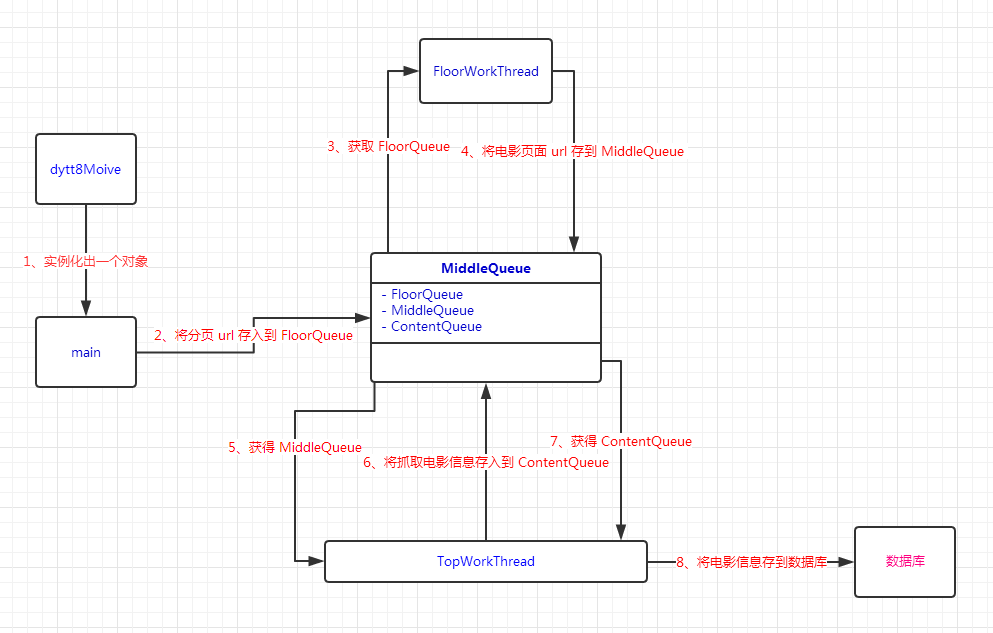
2-3.设计爬虫架构
根据爬取思路,我设计出爬虫架构。如下图所示:
2-4.代码实现
主要阐述几个重要的类的代码
2-4-1.main 类
主要工作两个:
第一,实例化出一个dytt8Moive对象,然后开始爬取信息。
第二,等爬取结束,将数据插入到数据库中。
处理爬虫的逻辑代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
|
LASTEST_MOIVE_TOTAL_SUM = 6
THREAD_SUM = 5
def startSpider():
LASTEST_MOIVE_TOTAL_SUM = dytt_Lastest.getMaxsize()
print('【最新电影】一共 ' + str(LASTEST_MOIVE_TOTAL_SUM) + ' 有个页面')
dyttlastest = dytt_Lastest(LASTEST_MOIVE_TOTAL_SUM)
floorlist = dyttlastest.getPageUrlList()
floorQueue = TaskQueue.getFloorQueue()
for item in floorlist:
floorQueue.put(item, 3)
for i in range(THREAD_SUM):
workthread = FloorWorkThread(floorQueue, i)
workthread.start()
while True:
if TaskQueue.isFloorQueueEmpty():
break
else:
pass
for i in range(THREAD_SUM):
workthread = TopWorkThread(TaskQueue.getMiddleQueue(), i)
workthread.start()
while True:
if TaskQueue.isMiddleQueueEmpty():
break
else:
pass
insertData()
if __name__ == '__main__':
startSpider()
|
创建数据库以及表,接着再把电影信息插入到数据库的代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
| def insertData():
DBName = 'dytt.db'
db = sqlite3.connect('./' + DBName, 10)
conn = db.cursor()
SelectSql = 'Select * from sqlite_master where type = "table" and name="lastest_moive";'
CreateTableSql = '''
Create Table lastest_moive (
'm_id' INTEGER PRIMARY KEY,
'm_type' varchar(100),
'm_trans_name' varchar(200),
'm_name' varchar(100),
'm_decade' varchar(30),
'm_conutry' varchar(30),
'm_level' varchar(100),
'm_language' varchar(30),
'm_subtitles' varchar(100),
'm_publish' varchar(30),
'm_IMDB_socre' varchar(50),
'm_douban_score' varchar(50),
'm_format' varchar(20),
'm_resolution' varchar(20),
'm_size' varchar(10),
'm_duration' varchar(10),
'm_director' varchar(50),
'm_actors' varchar(1000),
'm_placard' varchar(200),
'm_screenshot' varchar(200),
'm_ftpurl' varchar(200),
'm_dytt8_url' varchar(200)
);
'''
InsertSql = '''
Insert into lastest_moive(m_type, m_trans_name, m_name, m_decade, m_conutry, m_level, m_language, m_subtitles, m_publish, m_IMDB_socre,
m_douban_score, m_format, m_resolution, m_size, m_duration, m_director, m_actors, m_placard, m_screenshot, m_ftpurl,
m_dytt8_url)
values(?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?);
'''
if not conn.execute(SelectSql).fetchone():
conn.execute(CreateTableSql)
db.commit()
print('==== 创建表成功 ====')
else:
print('==== 创建表失败, 表已经存在 ====')
count = 1
while not TaskQueue.isContentQueueEmpty():
item = TaskQueue.getContentQueue().get()
conn.execute(InsertSql, Utils.dirToList(item))
db.commit()
print('插入第 ' + str(count) + ' 条数据成功')
count = count + 1
db.commit()
db.close()
|
2-4-2.TaskQueue 类
维护 floorQueue、middleQueue、contentQueue 三个队列的管理类。之所以选择队列的数据结构,是因为爬虫程序需要用到多线程,队列能够保证线程安全。
2-4-3.dytt8Moive 类
dytt8Moive 类是本程序的主心骨。程序最初的爬取目标是 5 个电影栏目,但是目前只现实了爬取最新栏目。
如果你想爬取全部栏目电影,只需对 dytt8Moive 稍微改造下即可。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
| class dytt_Lastest(object):
breakoutUrl = 'http://www.dytt8.net/html/gndy/dyzz/index.html'
def __init__(self, sum):
self.sum = sum
@classmethod
def getMaxsize(cls):
response = requests.get(cls.breakoutUrl, headers=RequestModel.getHeaders(), proxies=RequestModel.getProxies(), timeout=3)
response.encoding = 'GBK'
selector = etree.HTML(response.text)
optionList = selector.xpath("//select[@name='sldd']/text()")
return len(optionList) - 1
def getPageUrlList(self):
'''
主要功能:目录页url取出,比如:http://www.dytt8.net/html/gndy/dyzz/list_23_'+ str(i) + '.html
'''
templist = []
request_url_prefix = 'http://www.dytt8.net/html/gndy/dyzz/'
templist = [request_url_prefix + 'index.html']
for i in range(2, self.sum + 1):
templist.append(request_url_prefix + 'list_23_' + str(i) + '.html')
for t in templist:
print('request url is ### ' + t + ' ###')
return templist
@classmethod
def getMoivePageUrlList(cls, html):
'''
获取电影信息的网页链接
'''
selector = etree.HTML(html)
templist = selector.xpath("//div[@class='co_content8']/ul/td/table/tr/td/b/a/@href")
return templist
@classmethod
def getMoiveInforms(cls, url, html):
'''
解析电影信息页面的内容, 具体如下:
类型 : 疾速特攻/疾速追杀2][BD-mkv.720p.中英双字][2017年高分惊悚动作]
◎译名 : ◎译\u3000\u3000名\u3000疾速特攻/杀神John Wick 2(港)/捍卫任务2(台)/疾速追杀2/极速追杀:第二章/约翰·威克2
◎片名 : ◎片\u3000\u3000名\u3000John Wick: Chapter Two
◎年代 : ◎年\u3000\u3000代\u30002017
◎国家 : ◎产\u3000\u3000地\u3000美国
◎类别 : ◎类\u3000\u3000别\u3000动作/犯罪/惊悚
◎语言 : ◎语\u3000\u3000言\u3000英语
◎字幕 : ◎字\u3000\u3000幕\u3000中英双字幕
◎上映日期 :◎上映日期\u30002017-02-10(美国)
◎IMDb评分 : ◎IMDb评分\xa0 8.1/10 from 86,240 users
◎豆瓣评分 : ◎豆瓣评分\u30007.7/10 from 2,915 users
◎文件格式 : ◎文件格式\u3000x264 + aac
◎视频尺寸 : ◎视频尺寸\u30001280 x 720
◎文件大小 : ◎文件大小\u30001CD
◎片长 : ◎片\u3000\u3000长\u3000122分钟
◎导演 : ◎导\u3000\u3000演\u3000查德·史塔赫斯基 Chad Stahelski
◎主演 :
◎简介 : 暂不要该字段
◎获奖情况 : 暂不要该字段
◎海报
影片截图
下载地址
'''
contentDir = {
'type': '',
'trans_name': '',
'name': '',
'decade': '',
'conutry': '',
'level': '',
'language': '',
'subtitles': '',
'publish': '',
'IMDB_socre': '',
'douban_score': '',
'format': '',
'resolution': '',
'size': '',
'duration': '',
'director': '',
'actors': '',
'placard': '',
'screenshot': '',
'ftpurl': '',
'dytt8_url': ''
}
selector = etree.HTML(html)
content = selector.xpath("//div[@class='co_content8']/ul/tr/td/div/td/p/text()")
imgs = selector.xpath("//div[@class='co_content8']/ul/tr/td/div/td/p/img/@src")
if not len(content):
content = selector.xpath("//div[@class='co_content8']/ul/tr/td/div/div/td/span/text()")
if not len(content):
content = selector.xpath("//div[@class='co_content8']/ul/tr/td/div/td/div/text()")
if not len(content):
content = selector.xpath("//div[@class='co_content8']/ul/tr/td/div/div/td/p/font/text()")
if len(content) < 5:
content = selector.xpath("//div[@class='co_content8']/ul/tr/td/p/font/text()")
if not len(content):
content = selector.xpath("//div[@class='co_content8']/ul/tr/td/div/div/td/p/span/text()")
if not len(content):
content = selector.xpath("//div[@class='co_content8']/ul/tr/td/div/div/td/div/span/text()")
if not len(content):
content = selector.xpath("//div[@class='co_content8']/ul/tr/td/div/div/td/font/text()")
if not len(content):
content = selector.xpath("//div[@class='co_content8']/ul/tr/td/div/div/td/p/text()")
if not len(imgs):
imgs = selector.xpath("//div[@class='co_content8']/ul/tr/td/div/div/td/img/@src")
if not len(imgs):
imgs = selector.xpath("//div[@class='co_content8']/ul/tr/td/div/div/td/p/img/@src")
if not len(imgs):
imgs = selector.xpath("//div[@class='co_content8']/ul/tr/td/div/div/td/div/img/@src")
if not len(imgs):
imgs = selector.xpath("//div[@class='co_content8']/ul/tr/td/div/td/div/img/@src")
if content[0][0:1] != '◎':
contentDir['type'] = '[' + content[0]
actor = ''
for each in content:
if each[0:5] == '◎译\u3000\u3000名':
contentDir['trans_name'] = each[6: len(each)]
elif each[0:5] == '◎片\u3000\u3000名':
contentDir['name'] = each[6: len(each)]
elif each[0:5] == '◎年\u3000\u3000代':
contentDir['decade'] = each[6: len(each)]
elif each[0:5] == '◎产\u3000\u3000地':
contentDir['conutry'] = each[6: len(each)]
elif each[0:5] == '◎类\u3000\u3000别':
contentDir['level'] = each[6: len(each)]
elif each[0:5] == '◎语\u3000\u3000言':
contentDir['language'] = each[6: len(each)]
elif each[0:5] == '◎字\u3000\u3000幕':
contentDir['subtitles'] = each[6: len(each)]
elif each[0:5] == '◎上映日期':
contentDir['publish'] = each[6: len(each)]
elif each[0:7] == '◎IMDb评分':
contentDir['IMDB_socre'] = each[9: len(each)]
elif each[0:5] == '◎豆瓣评分':
contentDir['douban_score'] = each[6: len(each)]
elif each[0:5] == '◎文件格式':
contentDir['format'] = each[6: len(each)]
elif each[0:5] == '◎视频尺寸':
contentDir['resolution'] = each[6: len(each)]
elif each[0:5] == '◎文件大小':
contentDir['size'] = each[6: len(each)]
elif each[0:5] == '◎片\u3000\u3000长':
contentDir['duration'] = each[6: len(each)]
elif each[0:5] == '◎导\u3000\u3000演':
contentDir['director'] = each[6: len(each)]
elif each[0:5] == '◎主\u3000\u3000演':
actor = each[6: len(each)]
for item in content:
if item[0: 4] == '\u3000\u3000\u3000\u3000':
actor = actor + '\n' + item[6: len(item)]
contentDir['actors'] = actor
if imgs[0] != None:
contentDir['placard'] = imgs[0]
if imgs[1] != None:
contentDir['screenshot'] = imgs[1]
ftp = selector.xpath("//div[@class='co_content8']/ul/tr/td/div/td/table/tbody/tr/td/a/text()")
if not len(ftp):
ftp = selector.xpath("//div[@class='co_content8']/ul/tr/td/div/div/td/table/tbody/tr/td/font/a/text()")
if not len(ftp):
ftp = selector.xpath("//div[@class='co_content8']/ul/tr/td/div/div/td/table/tbody/tr/td/a/text()")
if not len(ftp):
ftp = selector.xpath("//div[@class='co_content8']/ul/tr/td/div/div/td/div/table/tbody/tr/td/font/a/text()")
if not len(ftp):
ftp = selector.xpath("//div[@class='co_content8']/ul/tr/td/div/td/div/table/tbody/tr/td/a/text()")
if not len(ftp):
ftp = selector.xpath("//div[@class='co_content8']/ul/tr/td/div/td/table/tbody/tr/td/a/text()")
if not len(ftp):
ftp = selector.xpath("//div[@class='co_content8']/ul/tr/td/div/div/td/p/span/a/text()")
if not len(ftp):
ftp = selector.xpath("//div[@class='co_content8']/ul/tr/td/div/div/td/div/div/table/tbody/tr/td/font/a/text()")
if not len(ftp):
ftp = selector.xpath("//div[@class='co_content8']/ul/tr/td/div/div/td/span/table/tbody/tr/td/font/a/text()")
if not len(ftp):
ftp = selector.xpath("//div[@class='co_content8']/ul/tr/td/div/div/td/div/span/div/table/tbody/tr/td/font/a/text()")
contentDir['ftpurl'] = ftp[0]
contentDir['dytt8_url'] = url
print(contentDir)
return contentDir
|
getMoiveInforms 方法是主要负责解析电影信息节点并将其封装成字典。
在代码中,你看到 Xpath 的路径表达式不止一条。
因为电影天堂的电影详情页面的排版参差不齐,所以单单一条内容提取表达式、海报和影片截图表达式、下载地址表达式远远无法满足。
选择字典类型作为存储电影信息的数据结构,也是自己爬坑之后才决定的。
这算是该站点另一个坑人的地方。电影详情页中有些内容节点是没有,例如类型、豆瓣评分,所以无法使用列表按顺序保存。
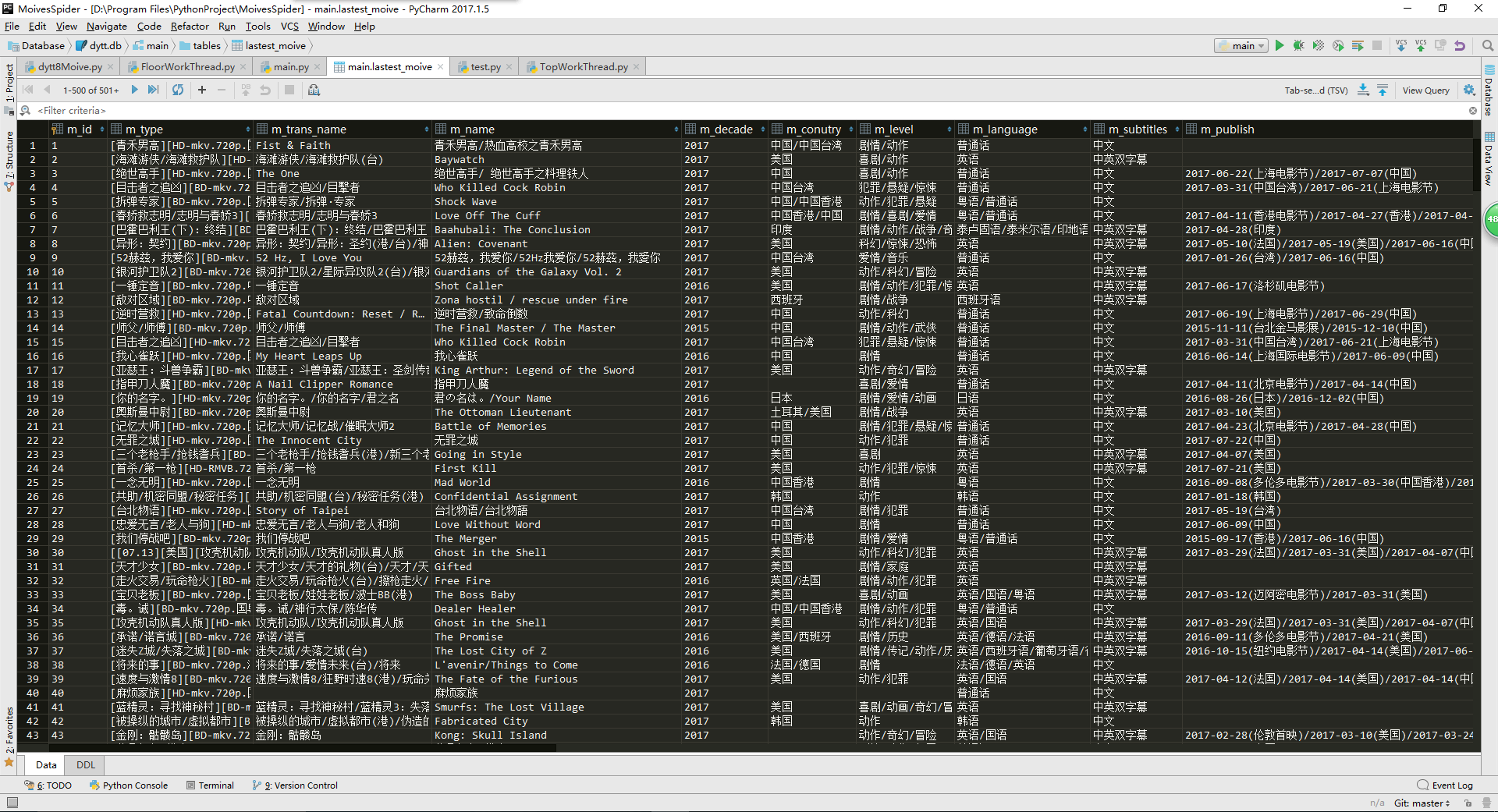
3.爬取结果
我这里展示自己爬取最新栏目中 4000 多条数据中前面部分数据。
4.源码
如果你想获取项目的源码, 点击按钮进行下载。
源码下载