在我的童年记忆中,电视台播放的动画片大多都是从日本、美国引进的。
很多动画片算是银幕上的经典,例如:《变形金刚》系列、《猛兽侠》、《蜘蛛侠》、《七龙珠》、《名侦探柯南》、《灌篮高手》、《数码宝贝》等。
但是国产的精品动画篇却寥寥无几,可能是当时我国动漫产业还处在起步阶段。
一晃几十年过去了,现在的国产动漫算是强势崛起,这也涌现出《斗破苍穹》、《秦时明月》、《天行九歌》等优秀的动画片。
2019年1月11日,一部国产动画电影《白蛇:缘起》在全国热映,一经上映便是好评如潮。
这部电影凭借惊艳的花屏,出色的配音取得猫眼 9.4 分、豆瓣 8.0 分的高分成绩。
既然是难得一见的精品,那么我去猫眼上爬爬网友的短评,看看网友们的观点。
1.分析页面
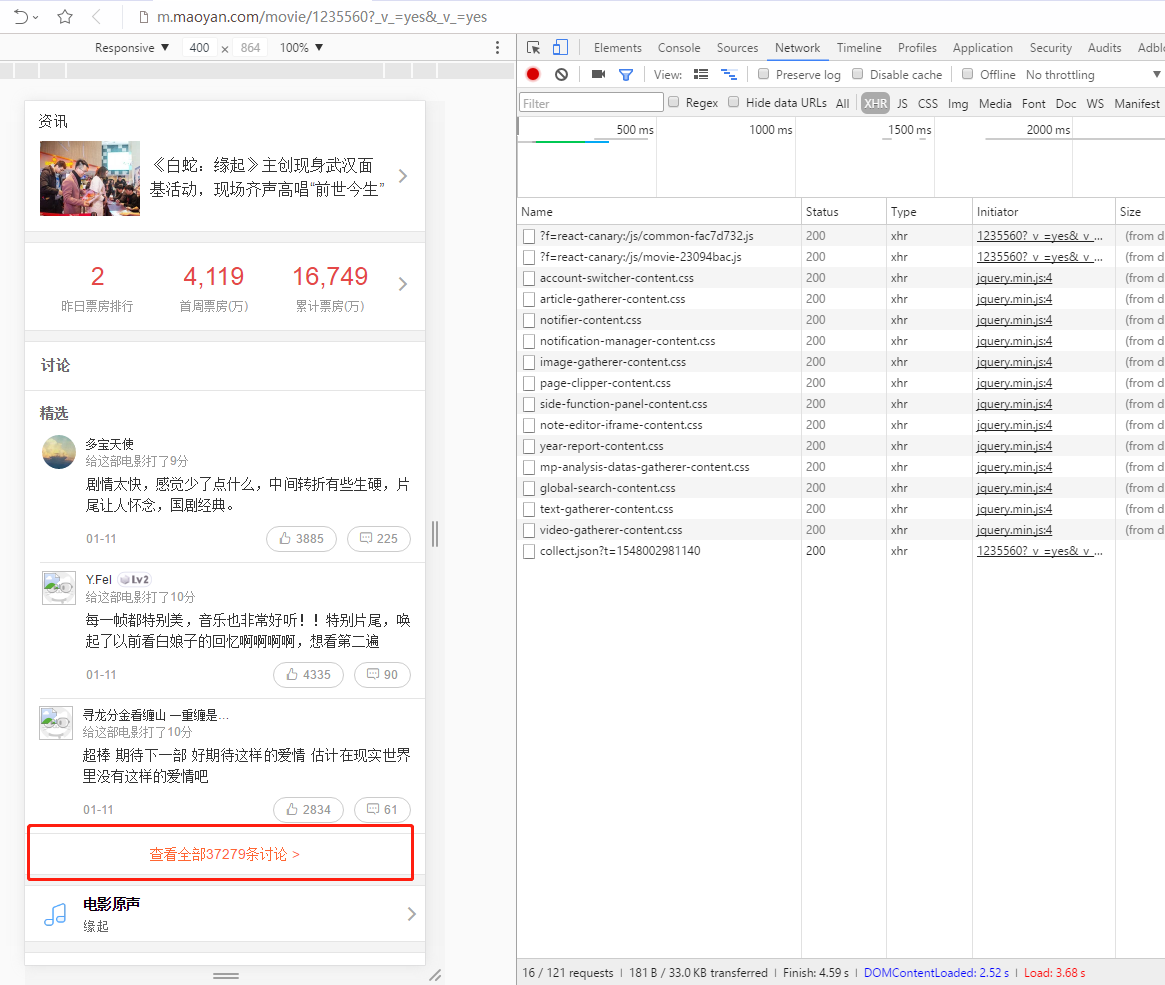
估计很多人经常光顾猫眼电影网,猫眼的反爬机制越来越严格,手段也越来越多。
如果选择“刚正面”,爬取 PC 端的页面,可能总体收益不高。
况且,PC 端的页面只有精彩短评,没有全部的网页评论数据。

因此,我选择转移战场,从手机页面入手,看看是否有收获。
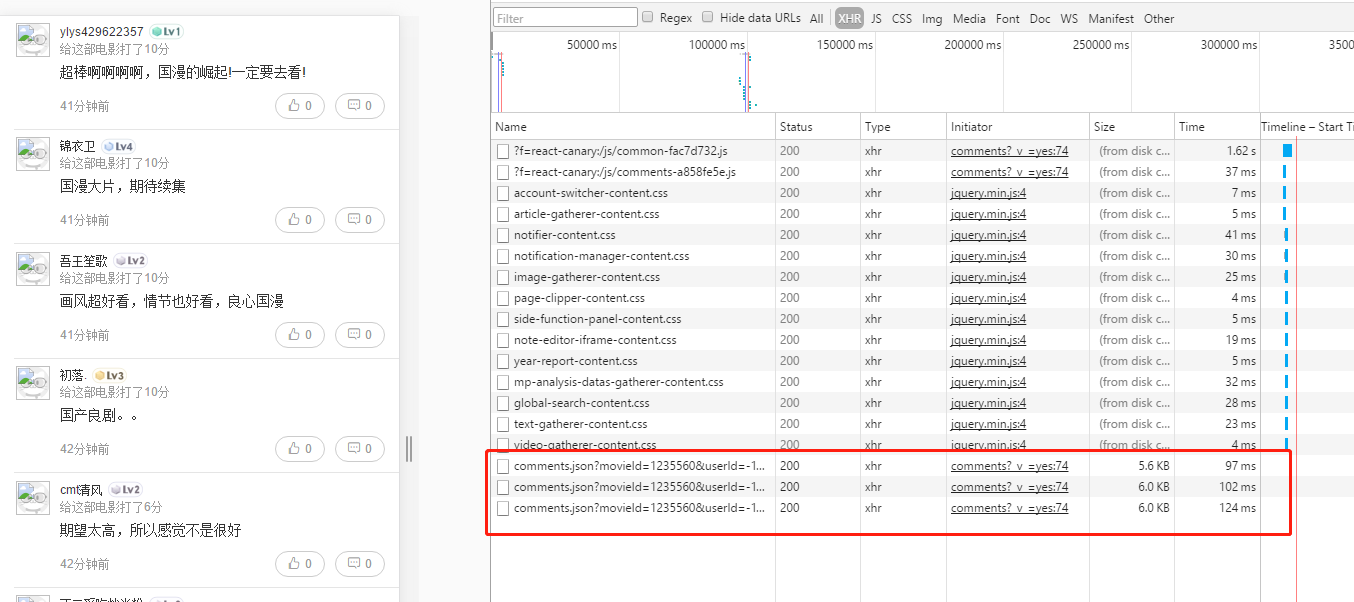
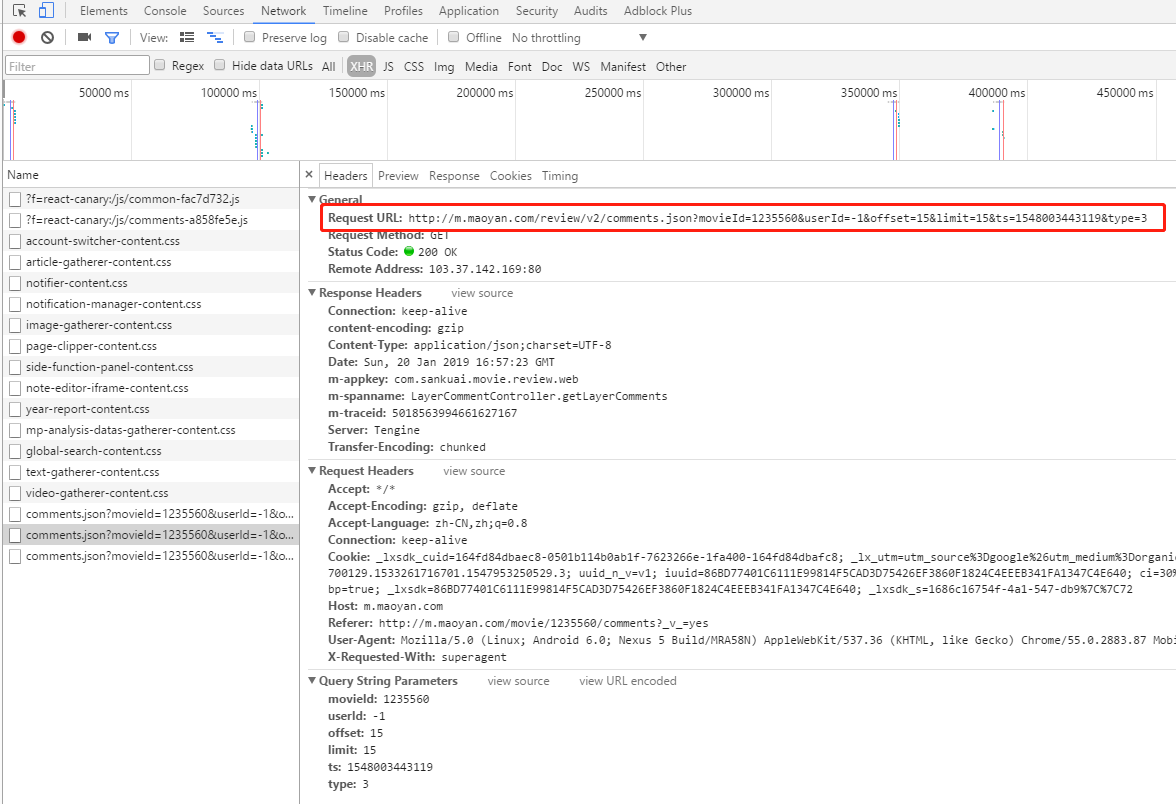
将浏览器选择以手机模式浏览器,结果发现手机网页有全部的短评数据。点击“查看全部讨论”,继续抓包分析。
随着鼠标滚动,自己浏览过几页短评数据之后,最终找到规律。
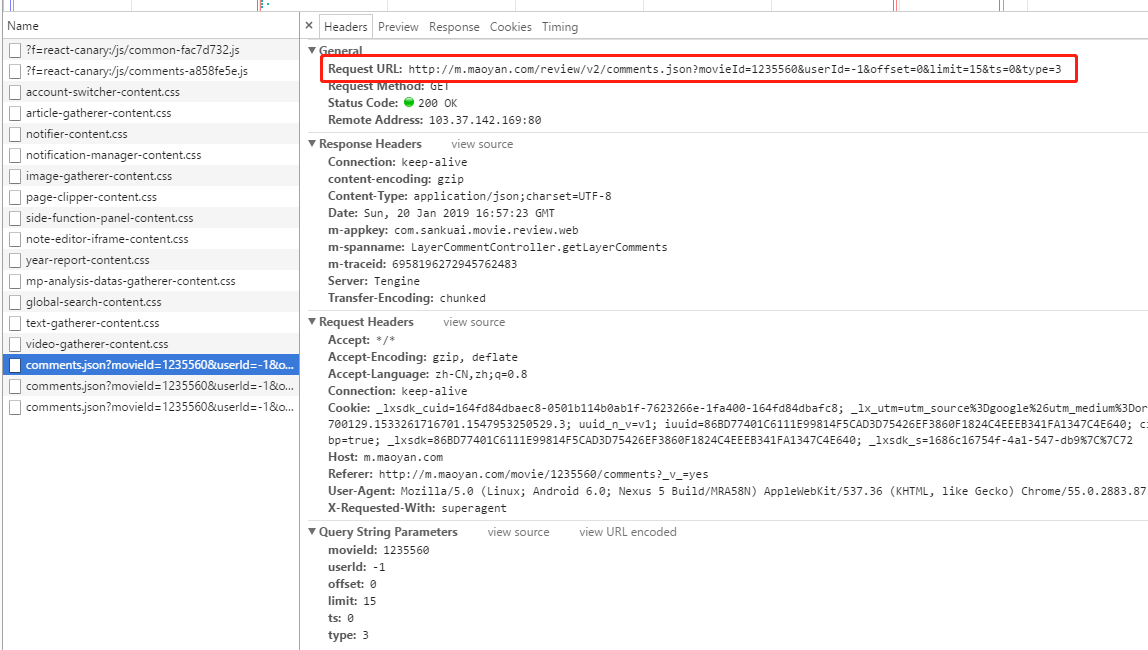
页面请求的地址是:
1
| http://m.maoyan.com/review/v2/comments.json?
|
后面携带一些参数:
1
2
3
4
5
6
| movieId=1235560&
userId=-1&
offset=0&
limit=15&
ts=0&
type=3
|
然后 offset 的值以 15 间隔递增。
我格式化请求结果,确认能获取到短评内容、点赞数等。
但是这个无法满足我的需求,我是想获取城市信息,后面想绘制地理热力图。
而目前这个接口没有城市信息。
因此,我选择逛逛各大搜索引擎,试下碰碰运气。
最后幸运女神帮了我一把,我找到别人已经挖掘到的猫眼短评接口。
1
| http://m.maoyan.com/mmdb/comments/movie/1235560.json?_v_=yes&offset=1
|
其中 1235560 表示电影的 id,offset 代表页数。
2.爬虫制作
因为短评数据量可能会比较多,所以我选择用数据库来存储数据。
后面方便进行数据导出、数据去重等。
自己从 json 数据结果中提取想要的数据,然后设计数据表并创建。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| def create_database(self):
create_table_sql = (
"CREATE TABLE IF NOT EXISTS {} ("
"`id` VARCHAR(12) NOT NULL,"
"`nickName` VARCHAR(30),"
"`userId` VARCHAR(12),"
"`userLevel` INT(3),"
"`cityName` VARCHAR(10),"
"`gender` tinyint(1),"
"`score` FLOAT(2,1),"
"`startTime` VARCHAR(30),"
"`filmView` BOOLEAN,"
"`supportComment` BOOLEAN,"
"`supportLike` BOOLEAN,"
"`sureViewed` INT(2),"
"`avatarurl` VARCHAR(200),"
"`content` TEXT"
") ENGINE=InnoDB DEFAULT CHARSET=utf8mb4".format(self.__table)
)
try:
self.cursor.execute(create_table_sql)
self.conn.commit()
except Exception as e:
self.close_connection()
print(e)
|
然后构造 Session 会话、请求头 headers 和 url 地址。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| """ 构造会话 Session 抓取短评 """
session = requests.Session()
movie_url = 'http://m.maoyan.com/mmdb/comments/movie/1235560.json?_v_=yes&offset={}'
headers = {
'User-agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Mobile Safari/537.36',
'Accept-Encoding': 'gzip, deflate',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Host': 'm.maoyan.com',
'Accept-Language': 'zh-CN,zh;q=0.8',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'Upgrade-Insecure-Requests': '1',
}
|
接着请求 url 地址并解析返回的 Json 数据。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
| offset = 1
while 1:
print('============抓取第', offset, '页短评============')
print('============>>>', movie_url.format(offset))
response = session.get(movie_url.format(offset), headers=headers)
if response.status_code == 200:
""" 解析短评 """
data_list = []
data = {}
for comment in json.loads(response.text)['cmts']:
data['id'] = comment.get('id')
data['nickName'] = comment.get('nickName')
data['userId'] = comment.get('userId')
data['userLevel'] = comment.get('userLevel')
data['cityName'] = comment.get('cityName')
data['gender'] = comment.get('gender')
data['score'] = comment.get('score')
data['startTime'] = comment.get('startTime')
data['filmView'] = comment.get('filmView')
data['supportComment'] = comment.get('supportComment')
data['supportLike'] = comment.get('supportLike')
data['sureViewed'] = comment.get('sureViewed')
data['avatarurl'] = comment.get('avatarurl')
data['content'] = comment.get('content')
print(data)
data_list.append(data)
data = {}
print('============解析到', len(data_list), '条短评数据============')
self.insert_comments(data_list)
else:
print('>=== 抓取第 ', offset, ' 失败, 错误码为 ' + response.status_code)
break
offset += 1
time.sleep(random.randint(10, 20))
|
完成解析数据工作之后,最后一步工作就是将数据插入到数据库中。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| def insert_comments(self, datalist):
""" 往数据库表中插入数据 """
insert_sql = (
"insert into "
"{} (id, nickName, userId, userLevel, cityName, gender, score, "
"startTime, filmView, supportComment, supportLike, sureViewed, avatarurl, content)"
"values(%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)".format(self.__table))
try:
templist = []
for comment in datalist:
if comment.get('gender') is None:
comment['gender'] = -1
data = (comment.get('id'),
comment.get('nickName'),
comment.get('userId'),
comment.get('userLevel'),
comment.get('cityName'),
comment.get('gender'),
comment.get('score'),
comment.get('startTime'),
comment.get('filmView'),
comment.get('supportComment'),
comment.get('supportLike'),
comment.get('sureViewed'),
comment.get('avatarurl'),
comment.get('content'))
templist.append(data)
self.cursor.executemany(insert_sql, templist)
self.conn.commit()
except Exception as e:
print('===== insert exception -->>> %s', e)
|
我因控制爬虫速率,暂时还没有完成爬取工作。至于爬取结果,详情见下篇文章关于电影短评的数据分析。
3.源码
如果你想获取项目的源码, 点击按钮进行下载。
源码下载